
You can trade crypto on the market without intermediaries, and the best way to work this way is P2P platforms. We decided to dive into the scheme to define the reasons for the popularity of P2P, its main pitfalls and ways to avoid them.
How P2P payments work in crypto
P2P is short for 'peer-to-peer'. P2P platform is a place where you can trade fiat for crypto, or vice versa, and exchange crypto for another coin without third-party involvement. The main principle of such services is the equality of every participant.
Many crypto companies have opened their own P2P platforms to make it easier for traders to interact with each other without third-party involvement. Such services, for example, can be found on popular exchanges such as Binance, KuCoin, and Bybit.
Here is how the classic P2P scheme works:
👥 The platform owner forms a base of merchants for the P2P service. As usual, participants make a profit on fees and market rate differences.
🤝 Someone who wants to buy or sell crypto without third-party involvement should visit the platform and pick a suitable offer. Filters help participants to reject inappropriate proposals.
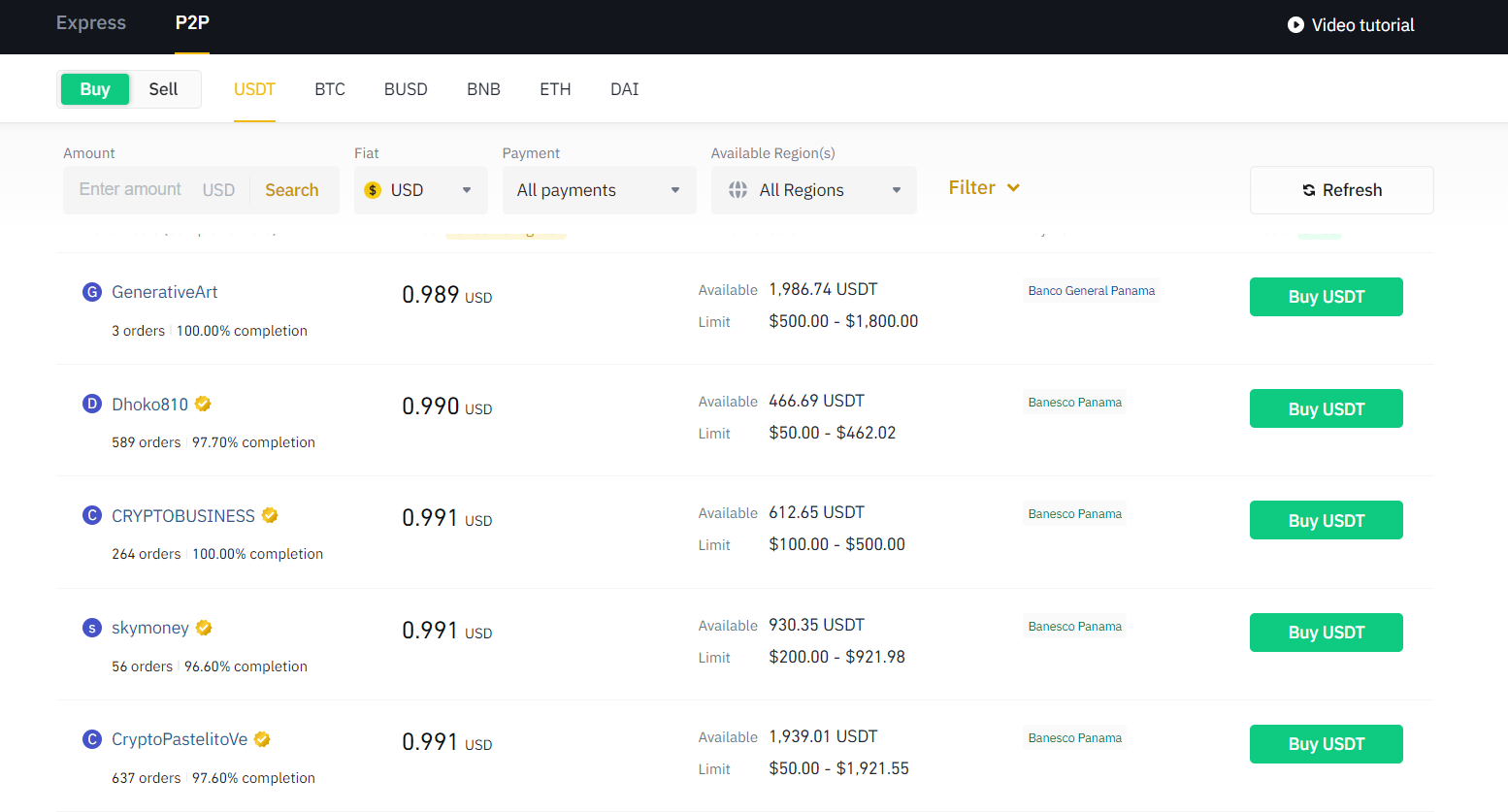
An example of a P2P platform interface (binance).
Let’s take a deeper look inside P2P deals. For instance, if a user wants to buy 2 Ethereum with USD and pay with a credit card, here are steps they should follow:
🦶 Set up a filter configuration based on your preferences and choose a suitable offer.
🦶 Open the deal.
🦶 Transfer USD directly to the merchant’s bank account.
The system will freeze the seller's crypto until he confirms the money received. If something goes wrong, the platform will transfer back the user's USD and unfreeze the merchant's crypto. In case of money receiving confirmation, the system will send coins to the buyer. When crypto is delivered, the deal is done.
Most P2P-platforms offer a limited list of crypto for deals. For example, it can be market capitalization leaders, such as bitcoin (BTC), Ethereum (ETH), and Tether (USDT). If you need to interact with other coins, you can convert them with an exchange.
Some P2P platforms are available for anonymous work. As an example, Bybit offers users without KYC a $1k limit. Everything you need is to create a profile with an e-mail or cell phone number. In that case the system opens a basic account.
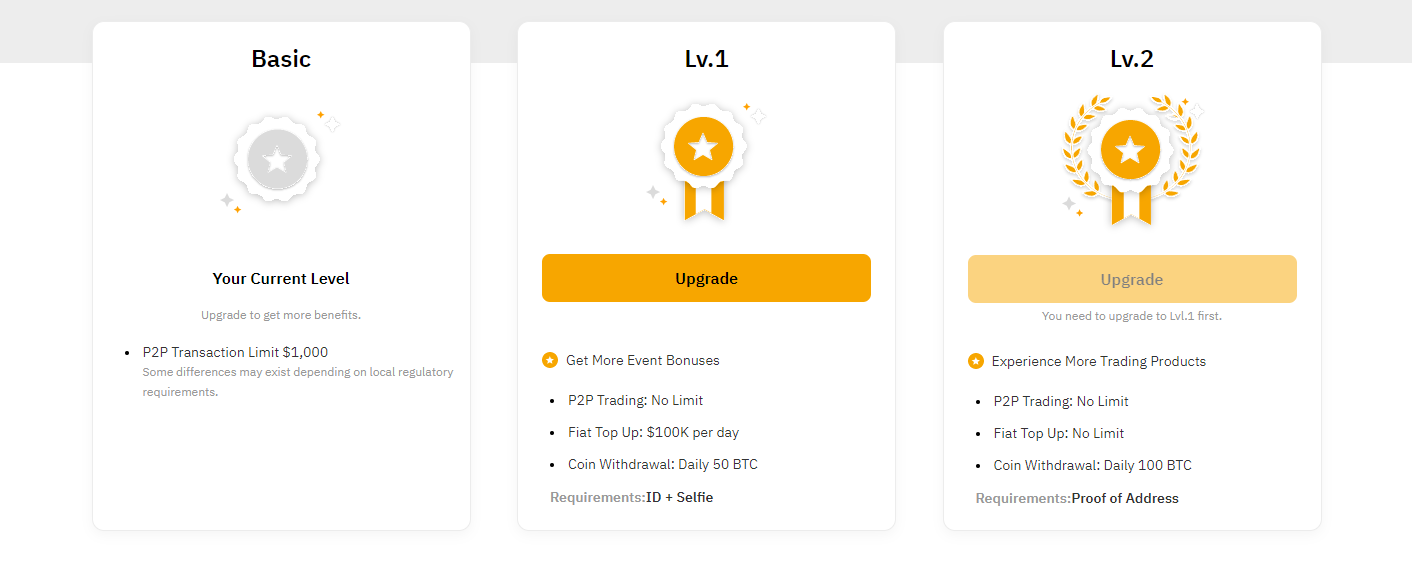
Bybit account settings.
Most P2P platforms offer services only to verified users. For example, KYC is the main condition for working with Binance, which exceeds other market participants in liquidity rate.
P2P high demand reasons
P2P in crypto is a good way to evade the additional fees you can face on exchanges and save extra money. At the same time, transactions that do not involve a third party are an excellent way to avoid financial market restrictions. It brings additional capabilities by opening a new gateway for transactions.
Users from Russia and other countries, for example, are currently unable to purchase cryptocurrency on foreign platforms using their Visa and MasterCard cards because payment systems in their respective regions have suspended operations. To solve this, people in restricted areas can make deals with each other through P2P.
P2P largely relies on both sides' equality and encourages participants with a rating system. It makes it easier to choose an offer and avoid scams. As deals occur on a certain company’s platform, its forms of engagement include an arbitrage system.
It means that an organisation is responsible for solving all the issues market participants can face. Exception is when one party to the transaction violates the rules. In that case, the rule breaker takes all the responsibility.
Is crypto P2P legal?
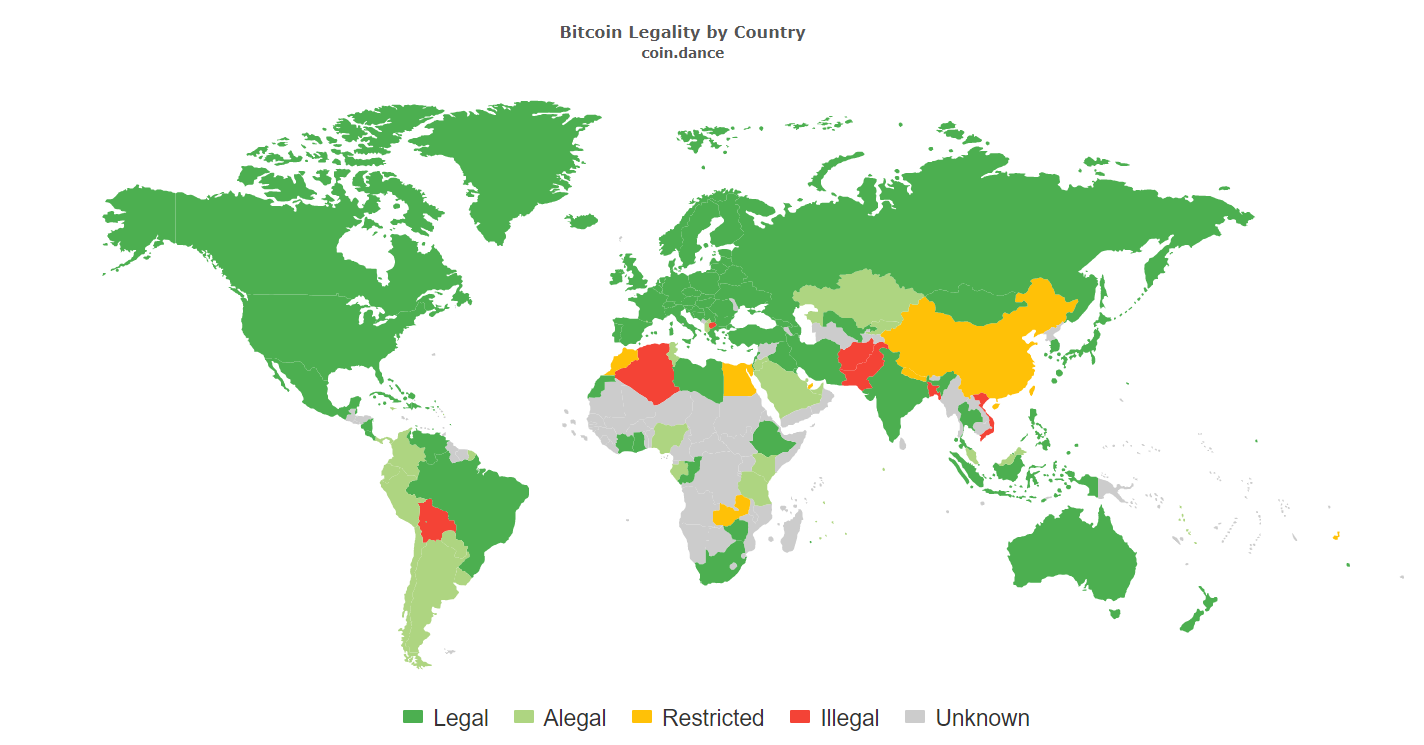
P2P deals are legal in the overwhelming majority of countries. Anyway, this question must be clarified according to the specific region you are interested in. Here are some countries where market participants will face no restrictions while working with P2P deals: USA, Canada, Denmark, France, Germany, Iceland, Japan, Mexico, Spain, and The United Kingdom.
You can see the countries where crypto P2P is not restricted with bitcoin legality map by CoinDance:
❗️Before entering the P2P crypto market, make sure that the platform you pick has a local license to operate in the financial market and offer crypto services.
Taxes issue
Short issue overview: in most cases, taxes must be paid. Everything depends on certain countries' legislation.
For example, in the United States, crypto is taxed up to 37%, just like property and investments, not virtual currency. The amount of taxes depends on several conditions, including the following: how long a market participant holds coins and how much profit he earned out of them.
The easiest way to estimate payment is to use special calculating services, for example, by Forbes. Don’t forget to check the report period. Delay may result in a penalty.
The main pitfalls of crypto P2P
The P2P market can hide some pitfalls that you can stumble upon. To be forewarned is to be prepared. That’s why we should pay attention to hidden risks.
🙅 Breach of contract terms
Sometimes P2P users face rule breaches. A merchant can try to change deal conditions. Such actions may lead to money losses and force watchdogs to file charges against market participants. The user can be engaged in the proceeding because of his agreement to interact with a third person, which was not mentioned in the original deal. Let’s dive into this with an example.
For instance, user A wants to sell Ethereum on P2P to merchant N with dollars via bank transfer. A opens the deal. Suddenly, he receives a message from N with an offer to approve payment from the third party. In original conditions, A was supposed to get dollars from verified by P2P manager N’s bank account.
An agreement to interact with an unknown third party is a huge risk. Such an offer can be a part of the money laundering process. To put it another way, a third party can send A dirty dollar and receive clear crypto. The new owner of suspicious money probably should anticipate the visit of AML-linked watchdogs.
By the way, the agreement to interact with third parties means P2P rules are breached. In that case, platform arbitrage can’t eliminate risks and protect users. P2P platform owners always ask market participants to report rule breaches and fraud, including third-party interaction. Unfortunately, many users prefer to ignore such calls. The thing is that scammers often offer the best rates. It makes market participants turn a blind eye to the obvious fraud.
🎣 Counterparty risk
While working on P2P, it is important to check all the details carefully. You should not blindly trust every signal. For instance, users should not approve deals before making sure that money was delivered exactly as it was supposed to be according to the deal conditions. Scammers can mislead market participants by passing fake SMS as a real platform notification or using other tricky methods.
Another common trick – scammers can send in private messages a fake payment link. Don’t click on it. It may cover fishing.
Network errors are not excluded too. For instance, a platform can send money received notification in a moment, when there are still no assets in the wallet. In that case users should contact support immediately.
How to stay safe?
🔺 Stay away from P2P platform rule breaches. It'll help you to eliminate the risk of being charged due to money laundering and other fraud.
🔺 Always check income before closing your deal. Don’t blindly trust notifications.
🔺 Don’t follow suspicious links in private chats while you are leading the deal.
🔺 Use reviews and rating systems. It helps to learn more about certain market participants and conditions they can offer.
🔺 Always send warning reports to the support service. It will help to protect you and other market participants from fraud.
If you want to make sure that all assets are under control and no one will touch them, just use platforms with a good reputation, like itez. You can use the service to buy crypto with a credit card just in a few steps with the best rates and the smallest fees.
This article is not an investment recommendation. The financial transactions mentioned in the article are not a guide to action. Itez is not responsible for possible risks. The user should independently conduct an analysis on the basis of which it will be possible to draw conclusions and make decisions about making any operations with cryptocurrency.








